12.6. 性能分析工具 perf
perf 是 Linux 平台常用的性能分析工具,可对程序完整运行过程或指定运行阶段进行监测,并支持函数级乃至指令级的性能统计和热点定位。借助 perf,可以评估程序性能并辅助查找瓶颈。perf 能监测多种指标,例如程序总运行时间、执行指令数、CPU 周期数、分支指令数量、分支预测失败率、Cache 命中情况和缺页异常次数等,这些指标在 perf 中称为事件。执行 perf list 可以查看当前环境支持的全部事件,实际分析时按需求选择即可。常见事件示例如下:
$ perf list
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-dcache-prefetches [Hardware cache event]
L1-dcache-store-misses [Hardware cache event]
L1-dcache-stores [Hardware cache event]
L1-icache-load-misses [Hardware cache event]
L1-icache-loads [Hardware cache event]
L1-icache-prefetch-misses [Hardware cache event]
L1-icache-prefetches [Hardware cache event]
branch-load-misses [Hardware cache event]
branch-loads [Hardware cache event]
...
perf 提供多个子命令,直接执行 perf 可查看完整列表。本节只介绍以下3类常用命令。
perf stat:在程序运行期间统计指定或默认事件,并在程序结束后把结果汇总输出到标准输出。
perf top:实时展示系统或指定进程的性能热点信息。
perf record/perf report:
perf record记录一段时间或完整运行过程中的性能事件,并保存到perf.data;perf report读取该文件并展示分析结果。
12.6.1. perf stat 的使用
perf stat 适合对程序进行概览性性能统计,常用命令格式如下:
perf stat [ -e <event> | --event=EVENT] [ -p <pid> | start_command ]
其中,-e 或 --event 用于指定监测事件;-p 用于监测已经运行的程序,后面跟随目标进程的 pid。例如,要统计进程号为17223的程序在监测期间的分支预测失败情况,可执行:
perf stat -e branches -e branch-misses -p 17223
若不显式指定事件,perf stat 默认监测 task-clock、context-switches、cpu-migrations、page-faults、cycles、instructions、branches、branch-misses 等事件。例如,使用 perf stat 全程监控名为 hot 的程序,命令和输出如下:
$ perf stat ./hot
Performance counter stats for './hot':
4,736.17 msec task-clock:u # 0.090 CPUs utilized
412,675 context-switches:u # 0.087 M/sec
0 cpu-migrations:u # 0.000 K/sec
45 page-faults:u # 0.010 K/sec
707,087,126 cycles:u # 0.149 GHz
517,319,871 instructions:u # 0.73 insn per cycle
113,415,431 branches:u # 23.947 M/sec
4,710,708 branch-misses:u # 4.15% of all branches
52.778699178 seconds time elapsed
6.000671000 seconds user
0.000000000 seconds sys
以上输出展示了 perf stat 默认事件的统计结果。第一列是事件耗时或计数值,第二列是事件名称,第三列是补充说明。评估程序性能时,最直观的指标是总执行时间,即 52.778699178 seconds time elapsed,表示程序从启动到结束经历的实际时间。最后两行 6.000671000 seconds user 和 0.000000000 seconds sys 分别表示程序消耗的用户态 CPU 时间和内核态 CPU 时间。
事件 task-clock 统计程序实际占用处理器的时间,单位为毫秒。示例中的结果为 4,736.17 毫秒。该值除以程序总执行时间,即为 CPU 占用情况,对应第三列的 0.090 CPUs utilized。该比值越高,说明程序越偏向 CPU 计算,而不是等待 I/O。对于计算密集型程序,单线程运行时该值可接近1;多线程运行时则可能接近实际使用的处理器核心数。
事件 context-switches 表示程序执行期间发生的上下文切换次数。示例中统计到 412,675 次。
系统调用、进程切换等操作都可能触发上下文切换。context-switches 与 task-clock 的比值表示单位时间内的上下文切换次数,也就是第三列显示的 0.087 M/sec。
perf 的部分事件需要 root 权限才能读取,例如 context-switches。权限不足时,相关事件结果可能为0。使用 perf 前,可将 /proc/sys/kernel/perf_event_paranoid 设置为 -1,或通过 root 用户、管理员权限(如 sudo)执行 perf 命令。
事件 cpu-migrations 统计程序在处理器核心之间迁移的次数。这里结果为 0,表示程序运行期间一直停留在同一个核心上。操作系统为了平衡多核负载,在满足一定条件时可能会把任务从一个核心迁移到另一个核心。
事件 page-faults 统计程序执行期间发生的缺页异常总数。示例结果为 45 次。该值与 task-clock 的比值表示单位时间内的缺页次数,即第三列中的 0.010 K/sec。
事件 cycles 表示程序执行期间消耗的处理器周期数。示例中为 707,087,126 次。cycles 与 task-clock 的比值可近似反映有效主频,即第三列的 0.149 GHz,明显低于当前主机处理器标称主频 2.3 GHz。
事件 instructions 统计程序执行的总指令数,示例结果为 517,319,871 次。instructions 与 cycles 的比值为 IPC(insn per cycle),表示平均每个 CPU 周期执行多少条指令,这里为第三列显示的 0.73。通常 IPC 越高,处理器利用越充分。当前龙芯处理器采用四发射结构,理论 IPC 最高可接近4。前文介绍指令重排优化时,就可以通过 IPC 的变化判断优化效果。
事件 branches 和 branch-misses 分别统计分支指令总数和分支预测失败次数。示例中二者分别为 113,415,431 次和 4,710,708 次。branch-misses 与 branches 的比值就是分支预测失败率,对应输出中的 4.15% of all branches。失败率越高,对性能影响越明显。前面介绍的循环展开技术可以减少分支指令执行次数。
如果默认事件不够用,可以通过 perf stat -e event_name 指定事件。例如,要查看程序执行期间一级数据缓存的加载情况,可使用 perf stat -e L1-dcache-load-misses,L1-dcache-loads。
$ perf stat -e L1-dcache-load-misses,L1-dcache-loads ./a.out
1,647,471 L1-dcache-load-misses:u # 0.01% of all L1-dcache hits
11,981,683,574 L1-dcache-loads:u
5.642483054 seconds time elapsed
LoongArch 架构处理器支持硬件预取,因此普通程序的 Cache 未命中率通常不会太高。示例中数据 Cache 未命中率为0.01%,说明数据加载指令命中情况较好。若用户程序出现较高的 Cache 未命中率,可继续使用 perf record 定位热点函数,再考虑调整函数实现逻辑,或使用 LoongArch 数据预取指令优化。
此外,perf stat 也支持按线程监测程序性能,示例如下:
//监测进程ID为1318程序的指令数量
perf stat --per-thread -e branch-misses -p 1318
12.6.2. perf top 的使用
perf stat 适合做总体统计,但无法直接定位到具体函数或汇编指令。perf top 可以实时显示性能热点,并进一步分析到函数级甚至指令级。其命令格式如下:
perf top [ -e <event> | --event=EVENT] [ -p <pid> ]
其中,-e 或 --event 用于指定监测事件;如果省略,默认事件为 cycles。若要实时监测进程号为17223的程序,可执行如下命令,结果如图10-2所示。
$ perf top -p 17223
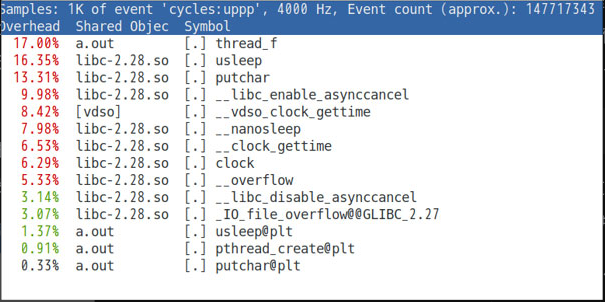
从图10-2可以看到,perf top 以函数为单位按性能占比从高到低排序,占比较高(超过5.00%)的函数会以红色标出。函数所在库和函数名分别显示在第二列和第三列。程序持续运行时,perf top 会不断刷新热点函数及其占比。
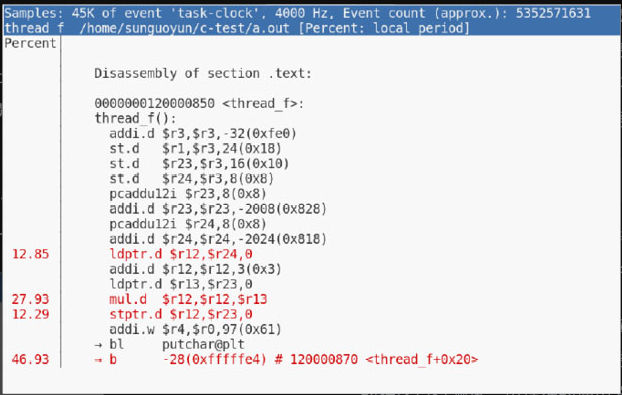
若要进一步查看热点函数内部的热点汇编指令分布,可用鼠标单击该函数所在行进入 annotate 模式,其效果等价于执行 perf annotate method_name。图10-3展示了最热函数 thread_f 展开后的信息。
12.6.3. perf record/report 的使用
perf top 能实时观察性能信息,但不会保存采样数据,因此不便于后续分析。perf record 用于解决这一问题:它可以记录一段时间或完整运行过程中的性能事件,并把结果保存为 perf.data。该文件不能直接阅读,需要用 perf report 解析并显示到终端。二者命令格式如下:
perf record [ -e <event> | --event=EVENT] [ -p <pid> | start_command ]
perf report [ file_name ]
perf record 的默认监测事件同样是 cycles。若要指定其他事件,可使用 -e 或 --event。采样既可以从程序启动前开始,也可以在程序运行过程中通过 -p 指定进程号开始。perf report 默认读取当前目录下的 perf.data;若文件位于其他目录,或文件名已改变,可显式指定路径和文件名。对已运行进程(进程号为17223)进行一段时间采样的命令如下:
perf record -p 17223
采样时间可适当延长,以便更准确地定位热点函数和热点指令。采样完成后(使用 Ctrl+C 停止),执行 perf report 加载 perf.data 并查看结果,其展示内容与图10-2中 perf top 的信息基本一致。
对于复杂服务程序,perf 能显著提升性能问题的定位效率。perf record 同样可以通过 -e event_name 指定事件,也可以通过 -p pid 对正在运行的程序采样。这里不再逐项列举,读者可结合自己的程序进行测试。更多用法可通过 perf record -h 查看。