6.1. 数据类型、数据对齐和字节序列
学习一个架构的ABI时,首先要了解它对高级语言(通常是C语言)中基本数据类型的大小、内存对齐和字节序的规定。掌握这些约定后,编写汇编程序时才能为不同数据类型选择合适指令,也能减少高级语言程序跨架构移植时出现错误的可能。
6.1.1. 数据类型
在LA32架构中,通用整数寄存器宽度为32位,因此从内存加载并参与运算的数据可以是字节(8位)、半字(16位)和字(32位),分别对应C/C++中的bool/char、short、int/long等类型。在LA64架构中,通用整数寄存器宽度为64位,因此数据还可以是双字(64位),对应C/C++中的long等类型。更具体的C/C++数据类型宽度及对齐方式如表5-1所示。
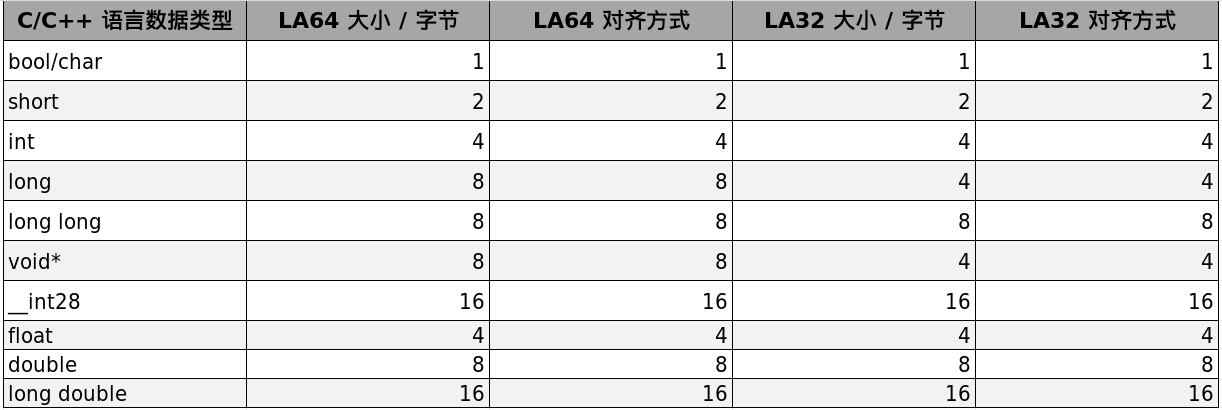
需要特别注意,long类型在LA32架构下为4字节,在LA64架构下为8字节。__int128和long double的大小都是16字节,这意味着加载或计算这两类数据时,在LA64架构下需要2个寄存器,在LA32架构下需要4个寄存器。
6.1.2. 数据对齐
为简化处理器和内存系统之间的硬件设计,许多计算机系统会对访存地址提出限制,要求被访问地址必须是数据类型大小的整数倍,这称为自然对齐。也就是说,读取或写入半字(2字节)时,地址应为2的倍数;访问字(4字节)时,地址应为4的倍数;访问双字(8字节)时,地址应为8的倍数。更完整的数据类型对齐规则见表5-1。下面给出几个对齐和非对齐访问示例:
// 假设寄存器r5的地址值为0x12000000
ld.w $r4, $r5, 0x3 // 0x12000003不能被4整除,为非对齐访问
ld.w $r4, $r5, 0x8 // 0x12000008能被4整除,为对齐访问
ld.d $r4, $r5, 0x5 // 0x12000005不能被8整除,为非对齐访问
LoongArch支持由硬件处理非对齐内存访问。也就是说,即使上面示例中存在非对齐访问,处理器仍能正常执行并得到正确结果,不会抛出非对齐异常。不过,从性能角度看,仍建议程序员尽量保证数据对齐,因为硬件处理非对齐访问通常比处理对齐访问更慢。
使用C语言编写程序时,编译器会自动处理对齐问题,使每个变量在内存中的起始地址满足自然对齐要求。例如,下面按顺序定义几个C语言变量:
char cVar;
int iVar;
short sVar;
long lVar;
编译器处理后,它们在内存中的存放顺序和地址如表5-2所示。
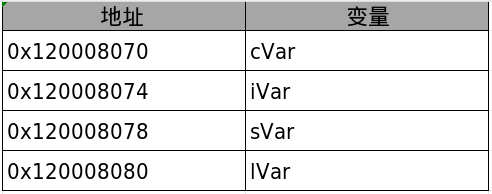
从表5-2可以看到,变量cVar虽然是char类型,只占1字节,但在内存中占用了4字节地址空间,目的是让后续整型变量iVar的地址(0x120008074)满足4字节对齐。cVar实际使用从起始地址0x120008070开始的4字节中的低8位,高24位未使用,这些未使用位称为填充(Padding)位。变量sVar虽然只需2字节,却占用8字节地址空间,也是为了让后续变量lVar的地址(0x120008080)满足8字节对齐。
C语言结构体中的成员布局同样遵循自然对齐原则。
6.1.3. 字节序列
字节序规定了半字、字、双字等多字节数据在内存中按字节排列的方式。常见字节序有大端序(Big Endian)和小端序(Little Endian)。假设C语言中一个int变量x的十六进制值为0x12345678,它在内存中按大端序和小端序存储的方式如图5-1所示。
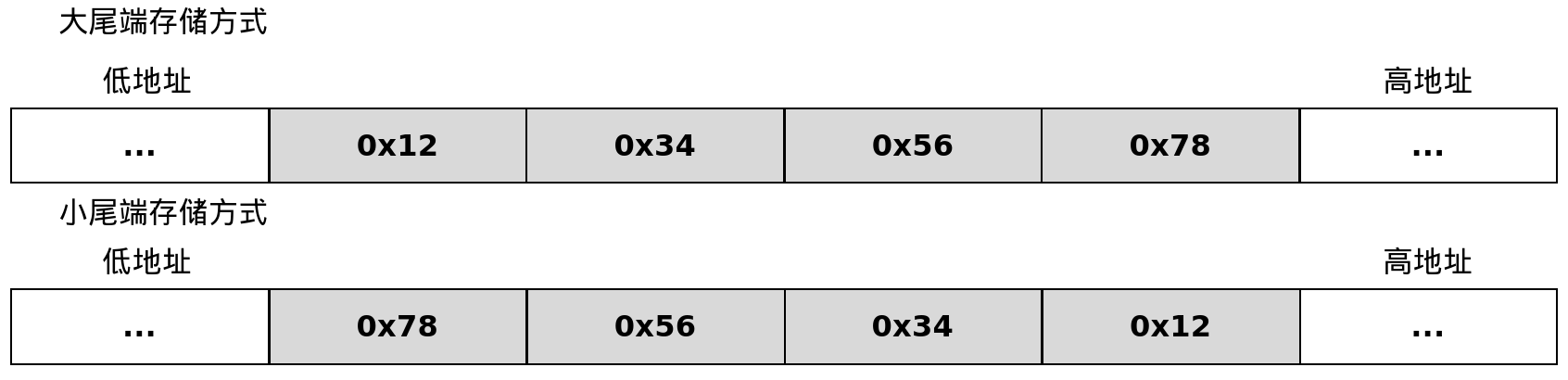
由图5-1可知,对于多字节数据,大端序从内存低地址开始依次存放数据高位到低位;小端序则相反,从内存低地址开始依次存放数据低位到高位。不同架构的字节序规定不同,例如x86和LoongArch采用小端序,ARM、MIPS的字节序则可以配置。
多数情况下,机器字节序对应用程序不可见,也无需特别处理,因为同一架构上的内存读写使用相同字节序。但在跨机器网络传输等场景中,如果通信双方采用不同字节序,而接收端没有对基本类型数据做字节序转换,就可能读到错误结果。这时就需要理解字节序并进行转换。验证当前机器字节序也很简单:向某个内存地址写入一个short或int数据,再从该内存起始地址读取1字节;如果读出的值等于写入数据的低8位,则为小端序,否则为大端序。