4.2. 访存指令
访存指令用于读取内存中的数据,或把数据写入内存。LoongArch中的访存指令可分为普通访存指令、边界检查访存指令和原子访存指令。边界检查访存指令会在访存前检查地址合法性;原子访存指令能够以原子方式完成对某个内存地址的“读-修改-写”操作序列。龙芯架构参考手册中,栅障指令并不归入访存指令,但由于它与数据访问顺序密切相关,本节也一并介绍。
4.2.1. 普通访存指令
普通访存指令用于对指定内存地址进行读写。读数据也称为加载,即把指定内存地址中的数据加载到寄存器;写数据也称为存储,即把寄存器中的数据保存到指定内存地址。读写的数据类型可以是字节、半字、字或双字。LoongArch支持的普通访存指令如表3-5所示。


表3-5中,加载指令读取小于64位的数据时(以后缀.b、.h、.w标识),通常需要先进行符号扩展,再写入指定寄存器。无论是内存加载到寄存器,还是寄存器写回内存,访存地址都有两种计算方式:一种是基址加立即数偏移(常称为base+offset),这类指令名前缀不带x,如ld.b、st.b;另一种是基址加寄存器偏移(常称为base+index),这类指令名前缀带x,如ldx.b、stx.b。使用基址加立即数偏移时,偏移量为12位有符号值(si12),可表示范围为[-2048, 2047]。
对于满足自然对齐要求的访存地址,可以使用表3-5中的ldptr.w、ldptr.d、stptr.w和stptr.d。这些指令的地址偏移量为16位值(si14<<2),因此相比ld.w、ld.d、st.w、st.d,可支持更大的地址偏移范围。
表3-5中的preld hint, rj, si12用于把指定内存地址所在的一个Cache行提前加载到Cache中。目标地址由寄存器rj的值加立即数si12得到。操作数hint共有0~31这32个可选值,用于表示预取类型。目前,hint=0表示load预取至一级数据Cache,hint=8表示store预取至一级数据Cache,其他hint值暂未定义,处理器执行时按nop处理。
4.2.2. 边界检查访存指令
边界检查访存指令的基本读写功能与普通访存指令相同,也用于从指定内存地址读取数据到寄存器,或把数据写入指定内存地址,数据类型可以是字节、半字、字或双字。二者区别在于,边界检查访存指令在真正读写前会先检查条件,确认目标地址是否处在给定地址范围内;如果条件不满足,就终止访存并触发边界检查例外。LoongArch支持的边界检查访存指令如表3-6所示。
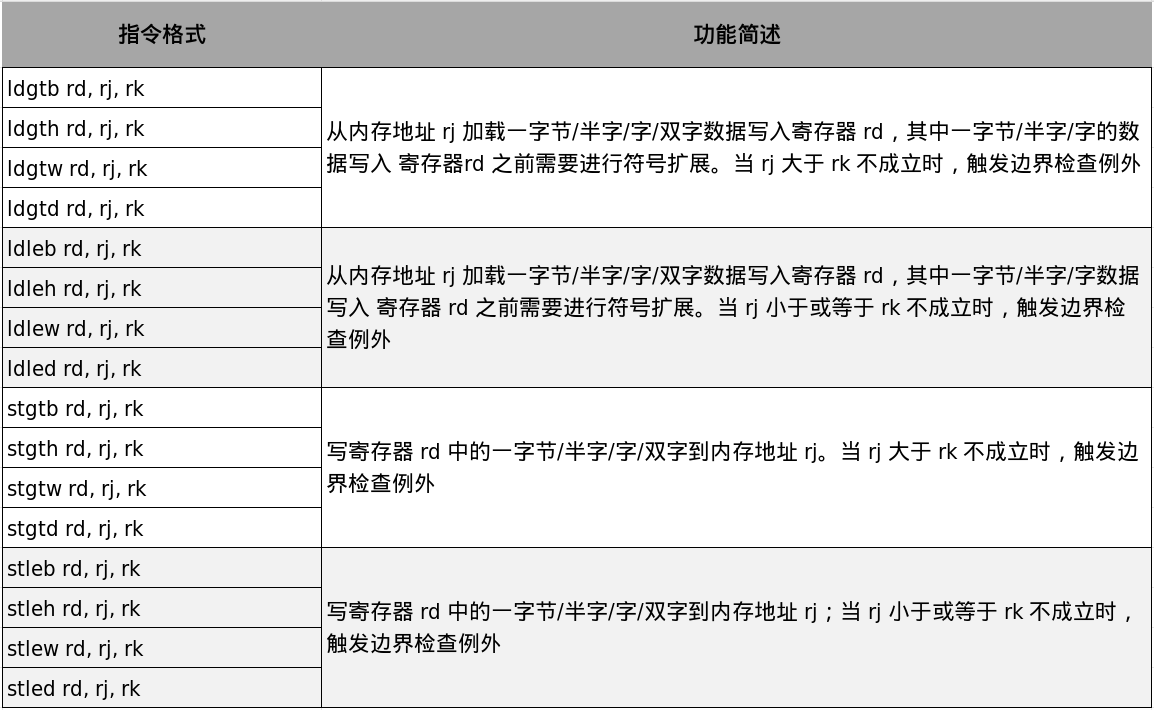
表3-6中,所有指令的访存地址都来自寄存器rj,rk表示访存边界。同时,这些指令都要求访存地址自然对齐,否则会触发非对齐例外。
带边界检查的访存指令常用于发现数组下标越界。假设定义数组int array[100],合法下标范围是0~99,访问array[-1]或array[101]都属于越界。C语言不像Java那样提供对程序员友好的动态防御机制,不能自动严格检查数组下标范围;而Java一旦发现数组越界,会抛出异常并终止程序。例如,C语言中的越界赋值语句如下:
array[101] = 1;
该语句可以用如下汇编指令实现:
addi.w $r13, $r0, 1(0x1) # 加载立即数1到寄存器r13
st.w $r13, $r12, 0 # 实现array[101] = 1。这里假设&array[101]为r12
执行st.w r13, r12, 0后,可能出现两类安全问题:程序立即异常,或者程序运行一段时间后才异常。编译器能够保证array[0]~array[99]所在内存区域可写,但无法保证array[101]所在区域的权限。如果该地址恰好落入不可写区域(例如只读代码区),st.w执行时会立即触发异常,常见异常信号为SIGBUS。如果该地址恰好可写,写操作仍会成功,但数据会写到数组范围之外,可能破坏其他合法变量或指针的值。程序继续运行后才可能出错或崩溃,调试时已经远离最初的错误现场,定位难度会明显增大。
为了尽早暴露问题并降低调试成本,可以使用带边界检查的访存指令实现更安全的数组访问。
Tip
边界检查访存指令仅在LA64架构上支持,在LA32架构上没有相关指令。如果要在LA32架构实现类似功能,可以使用其他基础逻辑运算指令完成。
4.2.3. 栅障指令
栅障分为数据栅障和指令栅障。数据栅障用于限制处理器核对某些访存指令进行乱序执行,指令栅障用于保证被修改后的指令能够被正确取出并执行。
Note
乱序执行:当CPU准备执行某条需要等待的指令(例如访存指令的读操作数因Cache Miss尚未准备好,或遇到比较耗时的乘法指令)时,可以先让排在后面且没有数据相关的指令执行,从而避免流水线阻塞带来的性能下降。
LoongArch支持的栅障指令如表3-7所示。

数据栅障通常有多种类型。读栅障(常称为LoadLoad)用于保证数据栅障前后的读内存指令保持顺序:只有栅障前的读内存指令执行完成后,栅障后的读内存指令才可以继续执行。写栅障(常称为StoreStore)用于保证栅障前后的写内存指令保持顺序。完全栅障(常称为AnyAny)用于保证栅障前后所有访存指令有序:只有栅障前的全部访存指令完成后,栅障后的访存指令才可以执行。
在表3-7的dbar hint指令中,hint用于指定同步对象和同步程度。hint默认值为0,表示完全栅障。目前,龙芯基础指令集仅实现了完全栅障,其他类型的栅障会在后续逐步支持。
表3-7中的ibar hint用于完成处理器核内部store操作与取指之间的同步,操作数hint为0。
Note
现代处理器通常采用多级缓存(Cache)结构。其中,处理器内私有的一级Cache又分为数据缓存(DCache)和指令缓存(ICache),分别用于存放程序数据和指令。由于数据缓存和指令缓存没有直接联系,当指令被动态修改(程序已经执行)时,需要软件保证修改后的指令被写回内存,并使对应ICache位置上的旧指令失效。
Note
弱一致性模型是存储一致性模型的一种。
在弱一致性模型中,同步操作和普通访存需要区分开来。当程序中存在写共享单元(或变量)时,程序员必须使用架构所定义的同步操作保护对写共享单元的访问,以保证多个处理器核对写共享单元的访问互斥,从而保证程序正确性。
这里所提的“架构所定义的同步操作”即栅障指令。
Note
数据相关:在程序中,如果两条指令访问同一个寄存器或内存单元,且这两条指令中至少有一条会写该寄存器或内存单元,则认为这两条指令存在数据相关。
例如,指令add.w r5,r4,r3和指令sub.w r7,r5,r6存在数据相关,因为二者都使用了r5,且sub.w的执行依赖add.w对r5的写入结果。
解决这类问题的一种方法,是在写进程中加入数据栅障指令dbar,以保证写数据和写标识的先后顺序。示例如下:
st.d val,data
dbar 0 # 确保其前后两条访存指令的顺序执行
st.d 1,tag
同样,读进程中的两条读访存指令如果没有数据相关,也可能被乱序执行,即可能在尚未判断标识区tag时提前读取数据区data。因此,读进程中也需要加入数据栅障来保证顺序:
# 读进程
ld.d reg, tag # 读标识区tag
dbar 0
beqz reg, L # 标识如果为0,则跳转到L执行nop
ld.d val, data # 否则证明标识区为1,执行读数据区data
L: nop
在多进程共享区域的数据读写中,加入dbar 0可以避免处理器乱序执行导致共享数据状态不一致。
4.2.4. 原子访存指令
原子访存指令用于保证对指定内存地址的“读-修改-写”操作序列具有原子性。也就是说,从执行效果看,整个过程不可分割,也不会被中途打断。其中,“修改”动作可以是两个源操作数交换、加法、与、或、异或、取最大值、取最小值,也可以是自定义动作。LoongArch支持两类原子访存指令:内存原子操作(Atomic Memory Operation,AMO)和连锁加载/条件存储(Load-Linked/Store-Conditional,LL-SC)。具体指令如表3-8所示。
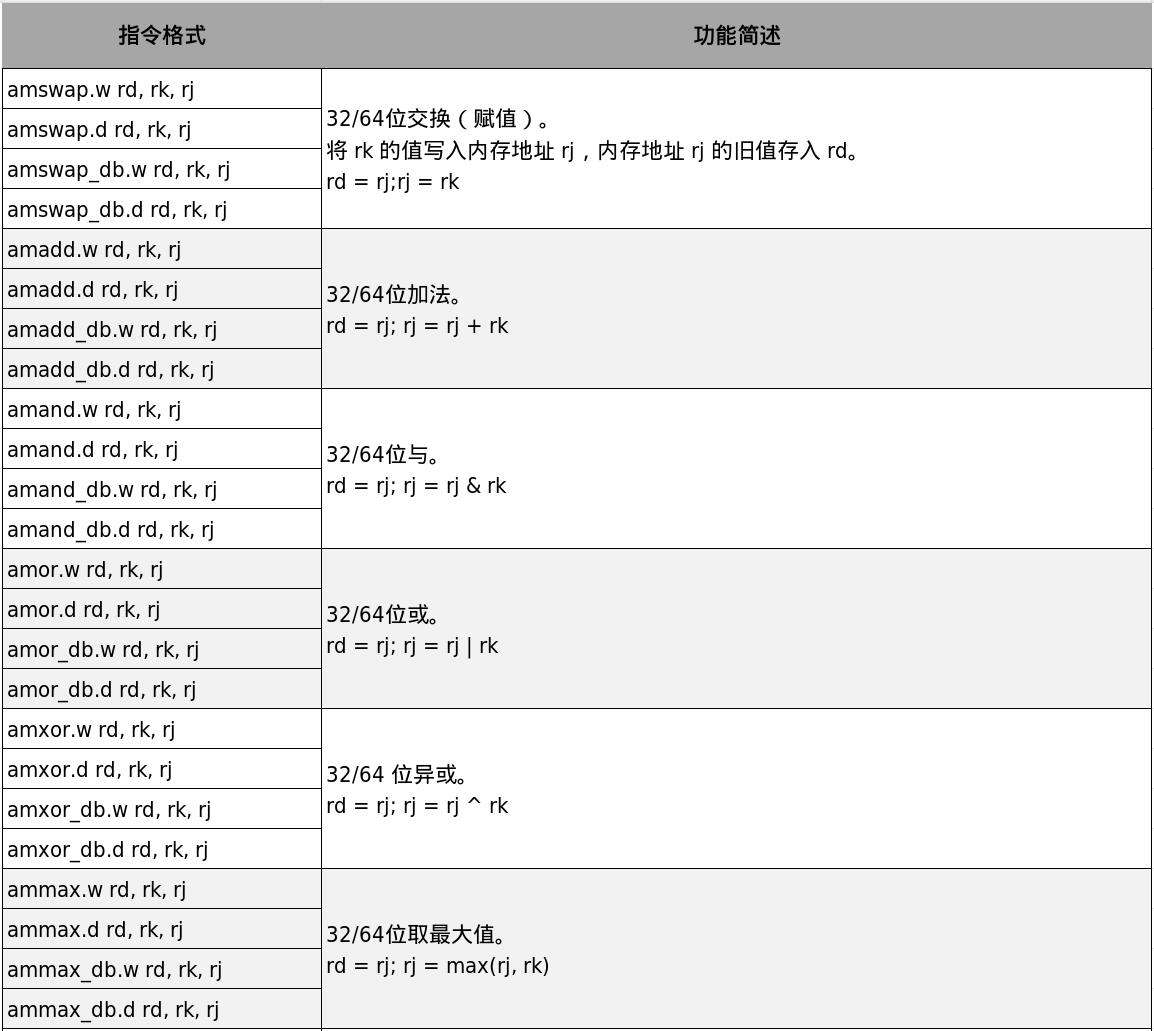
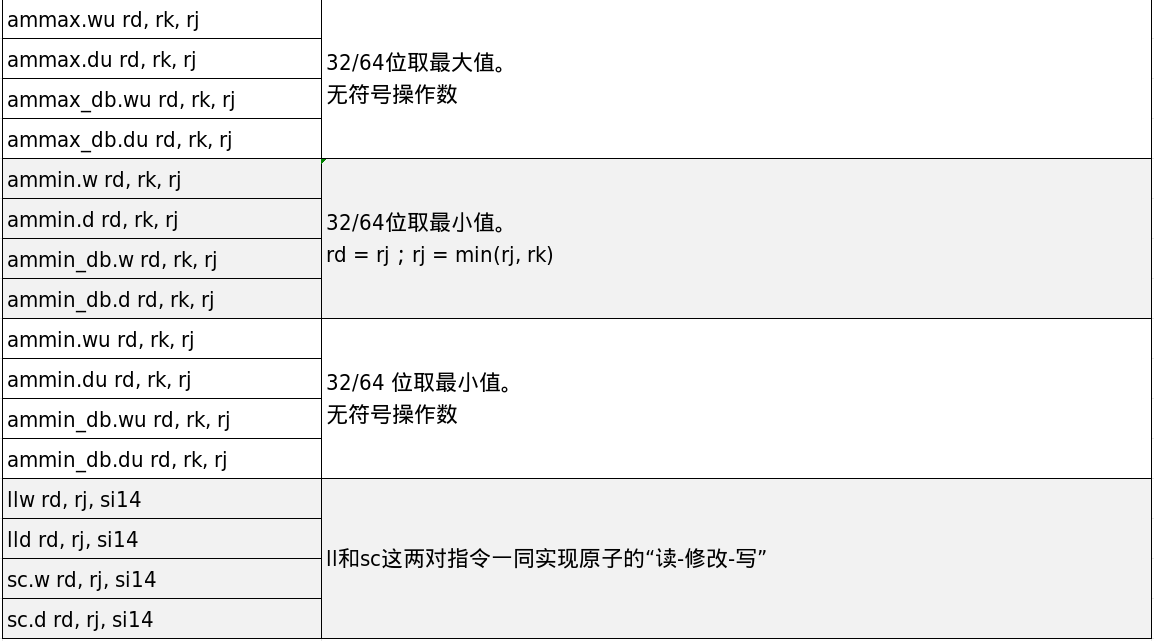
表3-8中,AMO指令使用寄存器rj保存待操作内存地址,内存旧值写入rd,内存新值由旧值和rk经过某种运算得到。具体运算包括交换(amswap)、加法(amadd)、与(amand)、或(amor)、异或(amxor)、取最大值(ammax)和取最小值(ammin)。
带_db标识的AMO指令,如amswap_db.w、amor_db.d等,除完成原子内存操作外,还具有数据栅障效果。也就是说,在这类AMO指令被允许执行前,同一处理器核中位于它之前的所有访存操作都已经完成;只有该AMO指令完成后,同一处理器核中位于它之后的访存操作才可以执行。这种效果就是前文所说的完全栅障,即AnyAny类型。
LL-SC中的ll.w、ll.d用于从指定内存地址(rj+si14)加载一个字或双字到寄存器rd,同时记录该内存地址并设置标记(LLbit置1)。sc.w、sc.d用于把寄存器rd的值写回指定内存地址(rj+si14)。执行sc时,处理器会检查LLbit:只有LLbit为1时才真正写入内存,并将rd置1;否则不写内存,并将rd置0表示写失败。在配对的LL-SC执行期间,如果其他处理器核对同一地址执行写操作,就会导致LLbit置0。
下面分别介绍两类原子访存指令的用法和注意事项。
连锁加载/条件存储(LL-SC)
LL-SC对某个内存单元的原子操作需要由软件维护。当软件必须完成一个成功的原子“读-修改-写”访存序列时,通常要构造循环反复执行LL-SC原子指令对,直到sc指令成功。为了支持这种循环,sc会把执行是否成功的标志写入寄存器rd。
什么情况下需要把a=a+1做成原子操作?sc又会在什么情况下写回失败?下面通过示例说明。假设两个线程都要对同一个共享变量a执行加1操作,每个线程的操作过程相同,都由3条指令完成。

假设两个线程各执行一次,如果a的初始值为3,期望结果应为5。实际结果可能是5,也可能是4。若结果为5,说明线程1完整执行后线程2再完整执行,或者线程2完整执行后线程1再完整执行。示例如下:

当线程1和线程2的3条指令交错执行时,最终结果可能变为4。可能的执行序列如下:

从时间线看,线程1先执行ld指令,把a加载到寄存器r4;随后线程1被中断,切换到线程2。线程2完整执行3条指令,把a从旧值3更新为4,然后线程2被中断。线程1再次运行时,并不知道变量a已经更新,寄存器r4中仍保存旧值3,因此继续执行后两条指令后,a仍为4。
对于这种需要数据同步的场景,可以使用LL-SC原子访存指令对,保证对变量a的“读-修改-写”过程具备原子性。使用LL-SC实现a=a+1时,即使遇到前述可能导致结果为4的交错执行序列,其逻辑如下:

内存原子操作(AMO)
AMO指令覆盖了大部分短小且常用的原子运算。对于前文使用LL-SC实现的a=a+1原子操作,改用AMO指令通常更直接、更方便。
Tip
AMO指令仅在LA64架构下支持。
Tip
使用原子访存指令时需要注意,rd和rj的寄存器号不能相同,rd和rk的寄存器号也不能相同,否则可能触发例外或导致执行结果不确定。