8.2. 汇编源文件中的汇编器指令
汇编指令是机器指令的可读形式,通常与机器指令一一对应。在GCC编译流程的汇编阶段,汇编器会把汇编指令翻译为机器指令,并写入目标文件。汇编器指令则不同,它面向汇编器本身,用来告诉汇编器如何定义变量和函数、如何组织目标文件中的汇编指令等。换句话说,汇编器指令是指导汇编器工作的指令。本节从符号定义和逻辑控制两个方面介绍汇编源文件中的汇编器指令。
8.2.1. 符号定义相关的汇编器指令
第06章介绍ELF目标文件格式时提到,函数和变量都可以称为符号。这个概念在汇编源程序中同样适用。编写汇编源程序时,也需要像使用高级语言一样,定义程序所需的常量、变量、函数等符号。与符号定义相关的常用汇编器指令如下。
定义一个字符串变量
在汇编源程序中定义字符串变量时,需要给出字符串名称、内容、大小、符号类型、对齐方式、作用域以及所在段等信息。下面是C语言字符串变量及其对应汇编器指令。
// c language
char str[10] = "hello";
# asm
.global str # 指定符号str的作用域为全局
.data # 指定符号str所在段为.data
.align 3 # 指定符号str为8字节对齐
.type str,@object # 指定符号str的类型为对象
.size str,10 # 指定符号str大小为10字节
str: # 指定符号名称为str
.ascii "hello\000" # 指定符号str的内容
示例中已经标出了该字符串定义涉及的信息。字符串内容除了可以用汇编器指令.ascii定义外,也可以使用.asciz和.string定义。三者都用于定义字符串,可以没有参数,也可以带多个由逗号分隔的字符串;汇编后,各字符串会依次存放在连续地址中。其中,.ascii不会在字符串末尾自动追加零字节;.asciz会自动在字符串后追加结束符\0,其中z表示zero。下面3种写法等价。
.ascii "hello\0"
.asciz "hello"
.string "hello"
.string实际上是.string8的缩写。汇编器指令.string会区分字符宽度,具体包括.string8、.string16、.string32和.string64,分别表示每个字符占8位、16位、32位和64位,实际存放还会受字节序影响。使用默认.string(即.string8)时,可把它看作与.asciz等价。例如,字符串.string "Hello World"在龙芯3A5000小端机器目标文件(.o文件)中的存放方式如下。
Addr Data
0: 6c6c6568 # ascii值 lleh
4: 6f77206f # ascii值 ow o
8: 00646c72 # ascii值 _dlr
如果定义为.string16 "Hello World",该字符串在汇编后的目标文件中存放方式如下。
Addr Data
0: 00650068 # ascii值 _e_h
4: 006c006c # ascii值 _l_l
8: 0020006f # ascii值 _ _o
c: 006f0077 # ascii值 _o_w
10: 006c0072 # ascii值 _l_r
14: 00000064 # ascii值 _ _d
为便于直观显示,注释中使用_代替ASCII表中的NUL值。
当源文件中的字符串只是临时且无名的字符串时,可以使用.LC0、.LC1等标签表示。
定义一个整型变量
在汇编源程序中定义整型变量与定义字符串变量类似,也需要给出变量名称、变量值、变量大小、变量类型、对齐方式、作用域和所在段等信息。下面是C语言整型变量及其对应汇编器指令。
static int int_v = 20;
.data
.align 2
.type int_v,@object
.size int_v,4
int_v:
.word 20
用于定义数据长度的汇编器指令包括.byte value、.half value、.word value和.dword value。.byte用于定义一字节(8位)地址空间,其他命令定义的空间大小与具体系统有关,value表示变量值。在LoongArch中,.half为2字节,.word为4字节,.dword为8字节。这里变量int_v是int类型,因此使用.word 20定义数据,.size为4字节。
定义一个函数
在汇编源程序中定义函数时,需要给出函数名称、函数汇编指令(可包含宏指令)、函数大小、符号类型、对齐方式、作用域和所在段等信息。下面是C语言函数及其对应汇编器指令。
int add(int a,int b){
return a + b;
}
.text # 指定符号add数据存放在代码段
.align 2
.global add
.type add, @function
add:
add.w $a0, $a0, $a1
jr $r1
.size add,.-add
函数通常放在代码段,因此这里用.text指定符号add所在段。前面字符串变量和整型变量的类型都是@object,而函数add的类型应定义为@function,表示该符号是函数;.global add表示该函数是全局可见的。函数标签add:之后即可编写汇编指令实现函数功能,这里只有add.w和jr两条指令。
符号add的大小使用.size add, .-add定义,其中add是符号(函数)名称,.-add表示当前位置(.)减去函数add起始位置,也就是函数指令占用的内存大小。当前函数共有2条指令,即8字节。为什么不直接写.size add, 8?原因是很多汇编源文件中会使用可能扩展成多条机器指令的宏指令,例如li.w、li.d。函数实际占用空间要等汇编器完成机器指令翻译后才能确定,因此更适合用基于函数符号的动态计算方式定义大小。
符号定义相关的汇编器指令说明
(1)设置符号类型
设置符号类型的汇编器指令是.type,常见类型包括@function和@object,分别表示当前符号为函数和变量。
.type add, @function # 符号add的类型为函数
.type v1,@object # 符号v1的类型为变量(对象)
(2)设置符号大小
汇编器指令.size name, expression用于设置符号(变量或函数)的大小,name为符号名称。设置变量大小时,expression通常是正整数;设置函数大小时,expression通常写为.-name。
.size short_v,2 # 设置变量short_v的大小为2字节
.size main,.-main # 设置函数main的大小为当前位置减去main起始位置
(3)指定符号对齐方式
汇编器指令.align expr用于指定符号对齐方式,expr为正整数,表示接下来数据在目标文件中的存放地址如何对齐。不同架构对expr的含义可能不同,例如x86中.align 4表示4字节对齐,而LoongArch中表示按2的4次方对齐,即16字节对齐。
如果希望避免.align参数含义在不同架构间不一致带来的可移植性问题,可以使用.balign或.p2align。例如,.balign 4在任何架构上都表示4字节对齐。
(4)指定符号的作用域
与C语言类似,在汇编源文件中定义变量或函数符号时,也需要声明作用域,用于说明当前符号的可见范围。默认情况下,如果不指定作用域,该符号仅在当前汇编源文件内可见。常用作用域相关汇编器指令包括.globl symbol、.common symbol和.local symbol。
.globl symbol用于指定符号symbol全局可见,通常用于全局变量或非静态函数,使其对链接器(ld)处理的其他源文件可见。
Tip
出于兼容原因,.globl 还可以写作 .global。
.common symbol用于声明通用符号(Common Symbol)。这里的通用符号可理解为C语言中未初始化的全局变量。多个汇编源文件中出现同名通用符号时,链接阶段可能会将它们合并,并保留占用空间最大的一个。例如,两个汇编源文件a.S和b.S中都定义了名为v1的全局变量,但数据类型不同:
/* a.S */
.comm v1,4,4
/* b.S */
.comm v1,8,8
a.S中的v1为4字节,b.S中的同名v1为8字节。链接后,这两个源文件合并到一个目标文件中,最终只保留一个8字节的v1符号。
.local symbol用于声明类似C语言中未初始化局部静态变量的符号。
// c语言变量
static int static_v1;
# 汇编器指令
.local static_v1
8.2.2. 逻辑控制相关的汇编器指令
这里的逻辑控制包括指定符号数据存放段、常量设置和条件编译、本地标签与程序跳转、编译调试、文件引用、循环展开、宏定义等功能。
指定符号数据存放段
第06章介绍ELF目标文件格式时已经说明,汇编器会把程序中的不同内容放入不同段中,例如可执行机器指令放在代码段(.text),已初始化变量放在数据段(.data),未初始化变量放在.bss段。在汇编源文件中,可以使用.data subsection、.text subsection等汇编器指令,分别指定后续语句进入目标文件的数据段或代码段。当需要指定更精细的段类型时,可以使用.section name。
例如,7.2.1小节中定义的整型变量和函数add分别放在数据段和代码段。
.data # 指定接下来的数据存放到目标文件的数据段
str:
.ascii "hello\000"
.text # 指定接下来的数据存放到目标文件的代码段
add:
如果已知本程序中的字符串"hello\0"只用于输出到终端,也可以更精细地把它放入只读数据段。
.section .rodata # 指定接下来的数据存放到目标文件的.rodata段
str:
.ascii "hello\0"
常量设置和条件编译
汇编器指令.set symbol, expression可用于设置常量,功能类似C语言中的宏定义,也可以配合.if、.else、.endif等汇编器指令完成条件编译。例如,要实现有条件输出,代码如下:
.set FLAG,0
.LC0:
.ascii "Hello World1!\000"
.LC1:
.ascii "Hello World2!\000"
main:
addi.d $sp, $sp, -8
st.d $ra, $sp, 0
.if FLAG == 1
la.local $r4, .LC0
.else
la.local $r4, .LC1
.endif
bl $plt(puts)
.if FLAG == 1、.else和.endif表示:当宏值FLAG为1时,输出字符串“Hello World 1!”;否则输出“Hello World 2!”。当前源文件中.set FLAG, 0将FLAG定义为0,因此最终输出“Hello World 2!”。
与.set等价的命令还有.equ symbol, expression,同样用于把符号symbol的值设置为expression。
汇编器还提供若干与.if类似的条件判断命令,其变体如表7-1所示。
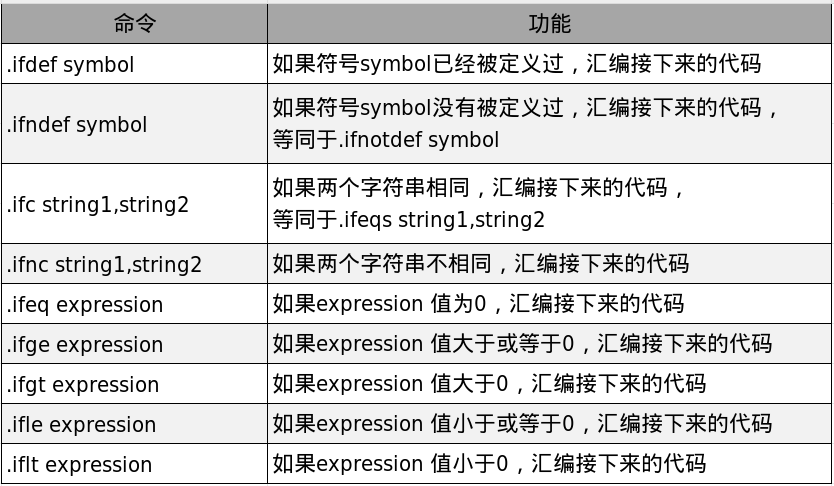
条件编译也可以直接使用C语言中的#ifdef、#else、#endif等预处理命令。使用C语言预处理命令时,汇编源文件不能直接交给汇编器编译,而应先使用GCC预处理工具cc1处理预处理命令。
本地标签和程序跳转
为便于编写跳转逻辑,汇编器提供本地标签(Local Label)。本地标签可使用编号(数字、字母、特殊字符或其组合)加冒号“:”的形式,即N:,其中N为正整数。引用同名标签时,可以使用Nf和Nb按方向查找:Nf中的f表示forward,指向后方紧邻的下一个同编号标签;Nb中的b表示backward,指向前方紧邻的上一个同编号标签。GNU汇编手册给出了如下示例:
1: branch 1f # 向后跳转到第3条(即1:branch 2f)位置
2: branch 1b # 向前跳转到第1条(即1:branch 1f)位置
1: branch 2f # 向后跳转到第4条(即2:branch 1b)位置
2: branch 1b # 向前跳转到第3条(即1:branch 2f)位置
该示例中有两组同名本地标签1:和2:。其中branch代表任意架构中的跳转指令;在LoongArch中,可以使用b、bl、beq、jirl等指令。整个跳转过程已经用行注释说明。如果改用4个不同标签名,上述过程可等价写为:
label_1:branch label_3
label_2:branch label_1
label_3:branch label_4
label_4:branch label_3
编译调试
可用于汇编阶段输出信息的指令包括.print string、.fail expression、.error string和.err。
.print string会让汇编器向标准输出打印一个字符串。
.fail expression会生成错误(error)或警告(warning)。当expression值大于或等于500时,汇编器输出警告;当expression值小于500时,汇编器as输出错误。expression默认值为0,因此也可以直接写.fail。
.err会在汇编过程中输出默认错误信息;如果需要自定义错误信息,可以使用.error string。这些指令在复杂宏嵌套或条件汇编场景中有助于定位问题。
调试指令示例如下:
.print "this is a test for print" # 输出信息:this is a test for print
.fail 499 # 输出信息:error: .fail 499 encountered
.fail # 输出信息:error: .fail 0 encountered
.err # 输出信息:error: .err encountered
.error "error happen" # 输出信息:error: error happen
文件引用
汇编源文件引用其他文件有两种方式。一种是使用汇编器指令.include "file",默认搜索路径为当前目录(Linux系统中表示为“.”);如果被引用文件不在同一目录,可通过汇编器命令行选项-I指定搜索路径。另一种是使用C语言预处理命令#include,这要求汇编源文件是.S文件,并通过GCC工具(具体为cc1)进行预处理。
下面是使用汇编器指令.include "file"引用文件的示例。
#ref.S
.text
add:
add.d $r4, $r5, $r4
jr $r1
#main.S
.include "ref.S"
这里有两个汇编源文件:ref.S和main.S。ref.S定义了名为add的函数。当main.S需要使用该函数接口时,可以通过.include "ref.S"把它包含进来。
循环展开
汇编器指令.rept count和.endr可把内部语句重复展开count次。例如:
.rept 3
nop
.endr
这表示通知汇编器在目标文件中生成3条nop指令,等价于直接编写:
nop
nop
nop
当需要根据实际情况插入不同数量的nop指令以实现地址对齐时,循环展开指令比较方便。
另一种循环展开命令是.irp symbol, values ...,用于用values中的各个值依次替代symbol并展开语句序列,同样以.endr结束。使用symbol时写作\symbol。例如,要把多个寄存器保存到函数栈上,可以写成:
.irp n,4,5,6,7,8,9,10,11,12
st.d $r\n, $sp, \n*8
.endr
这里实现的是把编号r4~r12的寄存器保存到函数栈。该命令在目标文件中最终展开为:
st.d $r4, $sp, 32(0x20)
st.d $r5, $sp, 40(0x28)
st.d $r6, $sp, 48(0x30)
st.d $r7, $sp, 56(0x38)
st.d $r8, $sp, 64(0x40)
st.d $r9, $sp, 72(0x48)
st.d $r10, $sp, 80(0x50)
st.d $r11, $sp, 88(0x58)
st.d $r12, $sp, 96(0x60)
宏定义
汇编器指令.macro name args的功能类似C语言宏定义,其中name为宏名称,args为参数,宏定义以.endm结束。例如,下面定义一个可根据参数生成不同数量nop指令的宏:
.text
.macro INSERT_NOP a
.rept \a
nop
.endr
.endm
这里使用.text表示后续指令存放到最终目标文件的代码段。宏名称为INSERT_NOP,参数为a。在宏定义体中使用参数时,格式为\参数,例如\a。.macro的参数可以为0个,也可以为多个;多个参数之间可以用逗号或空格分隔。使用时,直接调用宏并传入参数即可。例如,汇编源文件某处需要插入3条或7条nop指令时,可分别写为:
INSERT_NOP 3
INSERT_NOP 7